《Advanced Programming in the UNIX Environment》¶
参考资料:
环境配置¶
# Ubuntu environment
wget http://apuebook.com/src.3e.tar.gz
tar -zxv -f src.3e.tar.gz
sudo apt-get install libbsd-dev
cd apue.3e
make
sudo cp ./include/apue.h /usr/include/
sudo cp ./lib/libapue.a /usr/local/lib/
# compile
gcc filename.c -lapue
Chapter 1: UNIX System Overview¶
1.2 Unix Architecture¶
Operating System:
an operating system can be defined as the software that controls the hardware resources of the computer and provides an environment under which programs can run.

System Calls
The interface to the kernel.
Library Routines
Libraries of common functions are built on top of the system call interface, but applications are free to use both.
Shell
The shell is a special application that provides an interface for running other applications.
A shell is a command-line interpreter that reads user input and executes commands. The user input to a shell is normally from the terminal (an interactive shell) or sometimes from a file (called a shell script).
1.4 Files and Directories¶
File System
The UNIX file system is a hierarchical arrangement of directories and files. Everything starts in the directory called root, whose name is the single character/.
A directory is a file that contains directory entries.
Filename
The names in a directory are called filenames.
Two filenames are automatically created whenever a new directory is created: . (called dot) and .. (called dot-dot). Dot refers to the current directory, and dot-dot refers
to the parent directory. In the root directory, dot-dot is the same as dot.
Pathname
A pathname that begins with a slash is called an absolute pathname; otherwise, it’s called a relative pathname.
/* filename: 1.4.3.c */
#include "apue.h"
#include <dirent.h>
int main(int argc, char *argv[]) {
DIR *dp;
struct dirent *dirp;
if (argc != 2)
err_quit("usage: ls directory_name");
if ((dp = opendir(argv[1])) == NULL)
err_sys("can't open %s", argv[1]);
while ((dirp = readdir(dp)) != NULL)
printf("%s\n", dirp->d_name);
closedir(dp);
exit(0);
}
$ gcc 1.4.3.c -lapue
$ ./a.out .
.
1.4.3.c
..
a.out
$ ./a.out /dev
.
..
log
xconsole
core
stderr
stdout
stdin
fd
ptmx
urandom
zero
tty
full
random
null
shm
mqueue
pts
$ ./a.out /etc/ssl/private
can't open /etc/ssl/private: Permission denied
$ ./a.out /dev/tty
can't open /dev/tty: Not a directory
1.5 Input and Output¶
/* filename: 1.5.3.c */
#include "apue.h"
#define BUFFSIZE 4096
int main(int argc, char *argv[]) {
int n;
char buf[BUFFSIZE];
while ((n = read(STDIN_FILENO, buf, BUFFSIZE)) > 0)
if (write(STDOUT_FILENO, buf, n) != n)
err_sys("write error");
if (n < 0)
err_sys("read error");
exit(0);
}
$ gcc 1.5.3.c -lapue
$ ./a.out
>1 # 键入1
1
>2 # 键入 2
2
>^D # 键入 ctrl+D 结束
$ ./a.out > input.txt
>1
>2
>10
>^D
# 文件input.txt里按行依次写入了1 2 10
Standard I/O
/* filename: 1.5.4.c */
#include "apue.h"
int main(int argc, char *argv[]) {
int c;
while ((c = getc(stdin)) != EOF)
if (putc(c, stdout) == EOF)
err_sys("output error");
if (ferror(stdin))
err_sys("input error");
exit(0);
}
$ gcc 1.5.4.c -lapue
$ ./a.out
>1 # 键入1
1
>2 # 键入 2
2
>^D # 键入 ctrl+D 结束
$ ./a.out > input.txt
>1
>2
>10
>^D
# 文件input.txt里按行依次写入了1 2 10
1.6 程序和进程¶
进程和进程ID
/* filename: 1.6.2.c */
#include "apue.h"
int main()
{
printf("Hello world from process ID %ld\n", (long)getpid());
exit(0);
}
$ gcc 1.6.2.c -lapue
$ ./a.out
Hello world from process ID 854
$ ./a.out
Hello world from process ID 864
进程控制
/* filenmae: 1.6.3.c */
#include "apue.h"
#include <sys/wait.h>
int main(int argc, char *argv[]) {
char buf[MAXLINE]; // apue.h 中定义 #define MAXLINE 4096
pid_t pid;
int status;
printf("%% ");
while (fgets(buf, MAXLINE, stdin) != NULL) {
if (buf[strlen(buf) - 1] == '\n')
buf[strlen(buf) - 1] = 0;
if ((pid = fork()) < 0) {
err_sys("fork error");
}
else if (pid == 0) {
execlp(buf, buf, (char *) 0);
err_ret("couldn't execute: %s", buf);
exit(127);
}
if ((pid = waitpid(pid, &status, 0)) < 0)
err_sys("waitpid error");
printf("%% ");
}
exit(0);
}
$ gcc 1.6.3.c -lapue
$ ./a.out
% date
Sat Aug 24 12:47:18 CST 2019
% pwd
/home/coding/workspace/apue/learning_apue/chapter1
% ls
1.4.3.c 1.5.3.c 1.5.4.c 1.6.2.c 1.6.3.c a.out
% ^D
1.8 用户标识¶
/* filename: 1.8.c */
#include "apue.h"
int main()
{
printf("uid = %d, gid = %d\n", getuid(), getpid());
exit(0);
}
$ gcc 1.8.c -lapue
$./a.out
uid = 500, gid = 227
1.10 时间值¶
进程时间也被称为CPU时间,用以度量进程使用的中央处理器资源,基本数据类型是clock_t,一个进程维护3个进程的时间:
- 时钟时间,也叫墙上时钟时间(wall clock time),是进程运行时间的总量。对应打印信息的
real部分。 - 用户CPU时间。对应打印信息的
user。 - 系统CPU时间。对应打印信息
sys。
这里需要明确连个概念:
(1) 什么是用户态和内核态
(2) 时钟时间不是用户CPU时间与系统CPU之和,而是大于等于的关系。
用户态和内核态
因为操作系统的资源是有限的,如果访问资源的操作过多,必然会消耗过多的资源,而且如果不对这些操作加以区分,很可能造成资源访问的冲突。所以,为了减少有限资源的访问和使用冲突,Unix/Linux的设计哲学之一就是:对不同的操作赋予不同的执行等级,就是所谓特权的概念,与系统相关的一些特别关键的操作必须由最高特权的程序来完成。
Linux操作系统中主要采用了0和3两个特权级,分别对应的就是内核态和用户态。运行于用户态的进程可以执行的操作和访问的资源都会受到极大的限制,而运行在内核态的进程则可以执行任何操作并且在资源的使用上没有限制。很多程序开始时运行于用户态,但在执行的过程中,一些操作需要在内核权限下才能执行,这就涉及到一个从用户态切换到内核态的过程。比如C函数库中的内存分配函数malloc(),它具体是使用sbrk()系统调用来分配内存,当malloc调用sbrk()的时候就涉及一次从用户态到内核态的切换,类似的函数还有printf(),调用的是wirte()系统调用来输出字符串,等等。

发生从用户态到内核态的切换,一般存在以下三种情况:
1)当然就是系统调用:原因如上的分析。
2)异常事件: 当CPU正在执行运行在用户态的程序时,突然发生某些预先不可知的异常事件,这个时候就会触发从当前用户态执行的进程转向内核态执行相关的异常事件,典型的如缺页异常。
3)外围设备的中断:当外围设备完成用户的请求操作后,会像CPU发出中断信号,此时,CPU就会暂停执行下一条即将要执行的指令,转而去执行中断信号对应的处理程序,如果先前执行的指令是在用户态下,则自然就发生从用户态到内核态的转换。
注意:系统调用的本质其实也是中断,相对于外围设备的硬中断,这种中断称为软中断,这是操作系统为用户特别开放的一种中断。所以,从触发方式和效果上来看,这三种切换方式是完全一样的,都相当于是执行了一个中断响应的过程。但是从触发的对象来看,系统调用是进程主动请求切换的,而异常和硬中断则是被动的。
另外发现,real \neq user + sys,用户CPU时间和系统CPU时间之和为CPU时间,即命令占用CPU执行的时间总和。实际时间要大于CPU时间,因为Linux是多任务操作系统,往往在执行一条命令时,系统还要处理其它任务。
在8.17介绍了如何获取并计算三个时间。
第三章 文件I/O¶
第三章习题¶
3.1 当读/写磁盘文件时,本章中的函数确实是不带缓冲机制的嘛?
不带缓冲的概念是指每次read或write都调用内核中的一个系统调用。Unix系统在内核里有缓冲区高速缓存或页高速缓存,所以不带缓冲并不是没有缓存。比如系统缓冲区高速缓存的大小是100字节,每次write只是写入10字节,那么需要调用10次write才能填满缓冲区,系统才会flush缓冲区,然后写入磁盘。带缓冲区的I/O目的是为了减少系统调用的次数。带缓冲区的I/O多了一个缓冲流,假设流缓存的长度是50字节,当流缓存满时,再调用write写入内核缓存,相比之下只需两次系统调用。
无缓存IO操作数据流向路径:数据\rightarrow内核缓存区\rightarrow磁盘 标准IO操作数据流向路径:数据\rightarrow流缓存区\rightarrow内核缓存区\rightarrow磁盘
参考资料: https://github.com/MeiK2333/apue/tree/master/Chapter-03
第五章 标准IO库¶
5.4 缓冲¶
标准I/O库提供缓冲(buffer)的目的就是尽量减少read()和write()的调用次数。
- 全缓冲。只有在填满标准I/O缓冲区后才进行实际的I/O操作,典型的例子就是针对磁盘上的文件由标准库I/O实施全缓冲的。
- 行缓冲。在输入和输出中遇到换行符时,标准库I/O执行I/O操作。当流涉及一个终端时(比如标准输入和标准输出),通常使用行缓冲。
- 不带缓冲。标准I/O库不对字符进行缓冲存储。比如标准I/O函数
fputs写15个字符到不带缓冲的流中,或者利用write函数将一些字符写道相关联的打开文件中。比如标准错误流通常是不带缓冲的。
上面三个概念有一个很好的例子,就是在第八章8.1书中的样例程序,可以加深对于缓冲的理解;另外在学习第八章的exit和_exit的区别的时候,也可以加深对缓冲的理解。
冲洗(flush)表示标准库的写操作。当填满一个缓冲区或者调用函数fflush,缓冲区就会被冲洗。flush在Unix下有两种含义:
- 标准I/O库方面,
flush意味着将缓冲区的内容写到磁盘上 - 终端驱动程序上,
flush表示丢弃缓冲区中的数据。
行缓冲的两个限制:
- 标准I/O库收集每一行的缓冲区长度是固定的,所以只要缓冲区被填满,即使没有换行符,也要进行I/O操作。
- 任何时候只要通过标准I/O库从(1)一个不带缓冲的流,或者(2)一个行缓冲的流得到数据,那么就会冲洗所有行缓冲输出流。
系统默认的缓冲类型:
- 标准错误流不带缓冲。
- 指向终端设备的流,行缓冲的,否则全缓冲。
第7章 进程环境¶
7.3 进程终止¶
大多数Unix系统的shell都提供检查进程终止状态的方法。
例7-1:
//file name : 7.1.c
#include <stdio.h>
main()
{
printf("Hello world\n");
}
$ gcc -std=c90 7.1.c
$ ./a.out
Hello world
$ echo $?
13
$ gcc -std=c99 7.1.c
$ ./a.out
Hello world
$ echo $?
0
从main返回后立刻调用exit函数:
exit(main(argc, argv));
一个进程最多登记32个函数,函数由exit自动调用。用atexit函数来登记这些函数:
#include <stdlib.h>
int atexit(void (*func) (void));
/* filename: 7.3.c */
#include "apue.h"
static void my_exit1(void);
static void my_exit2(void);
int main() {
if (atexit(my_exit2) != 0) {
err_sys("can't register my_exit2");
}
if (atexit(my_exit1) != 0) {
err_sys("can't register my_exit1");
}
if (atexit(my_exit1) != 0) {
err_sys("can't register my_exit1");
}
printf("main is done\n");
return 0;
}
static void my_exit1(void) { printf("first exit handler\n"); }
static void my_exit2(void) { printf("second exit handler\n"); }
$ gcc 7.3.c -lapue
$ ./a.out
main is done
first exit handler
first exit handler
second exit handler
7.6 C程序的存储空间布局¶
- 正文段(.text段):这是由CPU执行的机器指令部分
- 正文段通常是共享的,频繁执行的程序(文本编辑器、C编译器、shell)再存储器也只需要一个副本
- 正文段通常是只读的,防止因意外被修改
- 初始化数据段(.data段):通常将它称作数据段(存放在磁盘可执行文件中,故而占磁盘空间)
- 它包含了程序中明确地赋了初值的变量:包括函数外的赋初值的全局变量、函数内的赋初值的静态变量
- 未初始化数据段(.bss段):在程序开始执行之前,内核将此段中的数据初始化为0或者空指针。
- 它包含了程序中未赋初值的变量:包括函数外的未赋初值的全局变量、函数内的未赋初值的静态变量
- 栈:临时变量以及每次函数调用时所需要保存的信息都存放在此段中
- 每次函数调用时,函数返回地址以及调用者的环境信息(如某些CPU 寄存器的值)都存放在栈中
- 最新的正被执行的函数,在栈上为其临时变量分配存储空间(通过这种方式使用栈,C 递归函数可以工作。递归函数每次调用自身时,就创建一个新的栈帧,因此某一次函数调用中的变量不影响下一次调用中的变量)
- 堆:通常在堆中进行动态存储分配
- 堆位于未初始化数据段和栈段之间
//file: 7.6.c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
extern char** environ;
int global1;
int global2 = 1;
int main()
{
//1.环境变量
printf("%s\n", "environment variables");
char **env = environ;
while(*env){
printf("(%p) (%p) %s\n",env,*env,*env);
env++;
}
printf("-------------------------------------\n");
//2.全局变量
printf("%s\n", "global variables");
printf("%p\n",&global1);
printf("%p\n",&global2);
printf("-------------------------------------\n");
//3.栈
printf("%s\n", "stack information");
int local;
char *localc = (char*)malloc(10);
printf("%p\n",&local);
printf("%p\n",&localc);
printf("-------------------------------------\n");
//4.堆
printf("%s\n", "heap information");
printf("%p\n\n",localc);
return 0;
}
environment variables
(0x7ffffdf2b028) (0x7ffffdf2b296) SHELL=/usr/bin/zsh
(0x7ffffdf2b030) (0x7ffffdf2b2a9) DISPLAY=:11.0
(0x7ffffdf2b038) (0x7ffffdf2b2b7) GNOME_TERMINAL_SERVICE=:1.36
.
.
.
(0x7ffffdf2b108) (0x7ffffdf2b5fc) LESS=-R
(0x7ffffdf2b110) (0x7ffffdf2b604) LSCOLORS=Gxfxcxdxbxegedabagacad
(0x7ffffdf2b118) (0x7ffffdf2b624)
-------------------------------------
global variables
0x7fe138a01024
0x7fe138a01010
-------------------------------------
stack information
0x7ffffdf2af14
0x7ffffdf2af18
-------------------------------------
heap information
0x7ffff6a77670
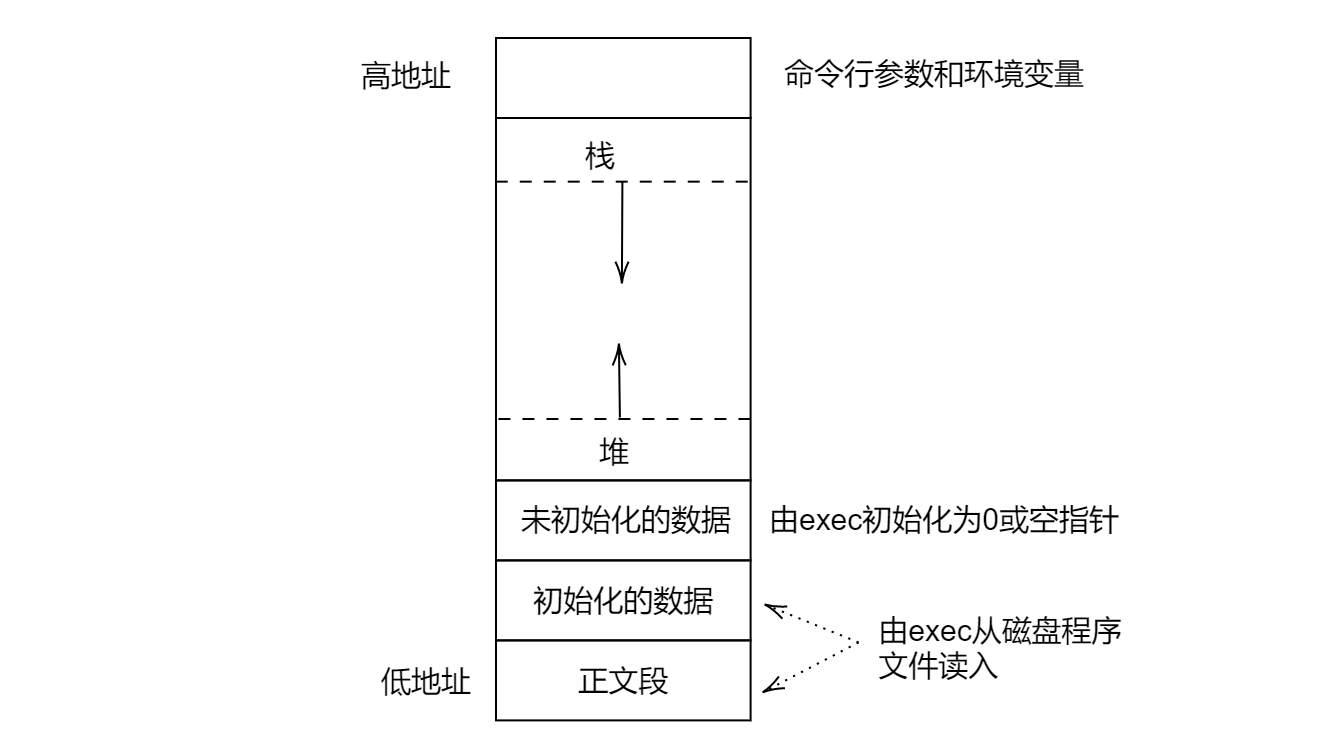
栈从高地址向低地址方向扩展,堆顶和栈顶之间的虚拟地址空间很大。
- **未初始化的数据**不存放在磁盘程序文件里,它们由exec初始化为0或空指针
- 存放在磁盘程序文件的只有**正文段和初始化数据段**
size命令可以查看正文段、数据段和bss段等信息:
# a.out 由 7.6.c产生的
$ size a.out
text data bss dec hex filename
2256 628 16 2900 b54 a.out
第4列和第5列是十进制和十六进制表示的3段总长度。
7.7 共享库¶
静态链接库与动态链接库 链接库按是否被编译到程序内部而分成动态与静态链接库
- 静态链接库
- 扩展名为.a,通常命名为
libxxx.a - 整合到可执行文件中,因此会导致可执行文件体积增大
- 可独立执行,而不需要再向外部要求读取链接库的内容
- 链接库升级时,需要重新编译生成可执行文件
- 动态链接库
- 扩展名为.so,通常命名为
libxxx.so - 动态链接库的内容并没有整合到可执行文件中,需要使用时才去读取链接库,因此可执行文件体积较小
- 不能独立执行,链接库必须存在
- 链接库升级时,通常不需要重新编译
- 共享库的优点
- 使得可执行文件中不再需要包含公用的库函数,而只需在所有进程都可引用的存储区中保存这种库例程的一个副本。程序第一次执行或者第一次调用某个库函数时,用动态链接方法将程序与共享库函数相链接,减少了每个可执行文件的长度
- 可以用库函数的新版本代替老版本而无需对使用该库的程序重新链接编辑(假定参数的数目和类型都没有改变)
- 共享库的缺点
- 动态链接增加了一些运行时开销。这种时间开销发生在该程序第一次被执行时,或者每个共享库函数第一次被调用时
可以通过gcc -static hello1.c命令阻止gcc使用共享库,可以通过size a.out查看可执行文件正文和数据段的长度变化
为了加速动态链接库的访问效率,一般需要将动态链接库载入内存中,从而避免读取磁盘。加载到高速缓存中的动态链接库所在的目录在文件/etc/ld.so.conf中指定,可以使用命令ldconfig将该文件中指定目录下的动态库读入缓存中
7.8 存储空间分配¶
第8章¶
系统调用跟我学2:https://www.ibm.com/developerworks/cn/linux/kernel/syscall/part2/
系统调用跟我学3:https://www.ibm.com/developerworks/cn/linux/kernel/syscall/part3/
孤儿进程和僵尸进程总结:https://www.cnblogs.com/Anker/p/3271773.html
(与僵尸进程关联的)Linux进程的5种状态:https://blog.csdn.net/kwame211/article/details/81532636
errno
为防止和正常的返回值混淆,系统调用并不直接返回错误码,而是将错误码放入一个名为errno的全局变量中。如果一个系统调用失败,你可以读出errno的值来确定问题所在。
errno不同数值所代表的错误消息定义在errno.h中,也可以通过命令"man 3 errno"来察看它们。
需要注意的是,errno的值只在函数发生错误时设置,如果函数不发生错误,errno的值就无定义,并不会被置为0。另外,在处理errno前最好先把它的值存入另一个变量,因为在错误处理过程中,即使像printf()这样的函数出错时也会改变errno的值。
实际操练
在Linux中,每个进程在创建时都会被分配一个数据结构,称为进程控制块(Process Control Block,简称PCB)。PCB中包含了很多重要的信息,供系统调度和进程本身执行使用,其中最重要的莫过于进程ID(process ID)了,进程ID也被称作进程标识符,是一个非负的整数,在Linux操作系统中唯一地标志一个进程,在我们最常使用的I386架构(即PC使用的架构)上,一个非负的整数的变化范围是0-32767,这也是我们所有可能取到的进程ID。其实从进程ID的名字就可以看出,它就是进程的身份证号码,每个人的身份证号码都不会相同,每个进程的进程ID也不会相同。
一个或多个进程可以合起来构成一个进程组(process group),一个或多个进程组可以合起来构成一个会话(session)。这样我们就有了对进程进行批量操作的能力,比如通过向某个进程组发送信号来实现向该组中的每个进程发送信号。
查看当前运行的进程:
$ ps -aux
#include<sys/types.h> /* 提供类型pid_t的定义 */
#include<unistd.h> /* 提供getpid()函数的定义 */
pid_t getpid(void);
getpid的作用很简单,就是返回当前进程的进程ID.
#include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
int main()
{
printf("process ID: %d\n", getpid());
return 0;
}
$ ./main
process ID: 135
pid_t类型即为进程ID的类型。事实上,在i386架构上(就是我们一般PC计算机的架构),pid_t类型是和int类型完全兼容的,我们可以用处理整形数的方法去处理pid_t类型的数据,比如,用"%d"把它打印出来。
fork()的函数原型:
#include<sys/types.h> /* 提供类型pid_t的定义 */
#include<unistd.h> /* 提供函数的定义 */
pid_t fork(void);
简单应用
#include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
int main()
{
pid_t pid;
/*此时仅有一个进程*/
pid=fork();
/*此时已经有两个进程在同时运行*/
if(pid<0)
printf("error in fork!");
else if(pid==0)
printf("I am the child process, my process ID is %d\n",getpid());
else
printf("I am the parent process, my process ID is %d\n",getpid());
}
I am the parent process, my process ID is 226
I am the child process, my process ID is 227
两个进程中,原先就存在的那个被称作“父进程”,新出现的那个被称作“子进程”。父子进程的区别除了进程标志符(process ID)不同外,变量pid的值也不相同,pid存放的是fork的返回值。fork调用的一个奇妙之处就是它仅仅被调用一次,却能够返回两次,它可能有三种不同的返回值:
- 在父进程中,fork返回新创建子进程的进程ID;
- 在子进程中,fork返回0;
- 如果出现错误,fork返回一个负值;
fork出错可能有两种原因:(1)当前的进程数已经达到了系统规定的上限,这时errno的值被设置为EAGAIN。(2)系统内存不足,这时errno的值被设置为ENOMEM。
wait的函数原型是:
#include <sys/types.h> /* 提供类型pid_t的定义 */
#include <sys/wait.h>
pid_t wait(int *status)
进程一旦调用了wait,就立即阻塞自己,由wait自动分析是否当前进程的某个子进程已经退出,如果让它找到了这样一个已经变成僵尸的子进程,wait就会收集这个子进程的信息,并把它彻底销毁后返回;如果没有找到这样一个子进程,wait就会一直阻塞在这里,直到有一个出现为止。
参数status用来保存被收集进程退出时的一些状态,它是一个指向int类型的指针。但如果我们对这个子进程是如何死掉的毫不在意,只想把这个僵尸进程消灭掉,(事实上绝大多数情况下,我们都会这样想),我们就可以设定这个参数为NULL,就象下面这样:
pid = wait(NULL);
如果成功,wait会返回被收集的子进程的进程ID,如果调用进程没有子进程,调用就会失败,此时wait返回-1,同时errno被置为ECHILD。
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
int main()
{
pid_t pc,pr;
pc=fork();
if(pc<0) /* 如果出错 */
printf("error ocurred!\n");
else if(pc==0){ /* 如果是子进程 */
printf("This is child process with pid of %d\n",getpid());
sleep(2); /* 睡眠2秒钟 */
}
else{ /* 如果是父进程 */
pr=wait(NULL); /* 在这里等待 */
printf("I catched a child process with pid of %d\n",pr);
}
exit(0);
}
$ ./main
This is child process with pid of 57
I catched a child process with pid of 57
如果参数status的值不是NULL,wait就会把子进程退出时的状态取出并存入其中,这是一个整数值(int),指出了子进程是正常退出还是被非正常结束的(一个进程也可以被其他进程用信号结束),以及正常结束时的返回值,或被哪一个信号结束的等信息。由于这些信息被存放在一个整数的不同二进制位中,所以用常规的方法读取会非常麻烦,人们就设计了一套专门的宏(macro)来完成这项工作,下面我们来学习一下其中最常用的两个:
1,WIFEXITED(status) 这个宏用来指出子进程是否为正常退出的,如果是,它会返回一个非零值。
(请注意,虽然名字一样,这里的参数status并不同于wait唯一的参数--指向整数的指针status,而是那个指针所指向的整数,切记不要搞混了。)
2,WEXITSTATUS(status) 当WIFEXITED返回非零值时,我们可以用这个宏来提取子进程的返回值,如果子进程调用exit(5)退出,WEXITSTATUS(status)就会返回5;如果子进程调用exit(7),WEXITSTATUS(status)就会返回7。请注意,如果进程不是正常退出的,也就是说,WIFEXITED返回0,这个值就毫无意义。
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
int main()
{
int status;
pid_t pc,pr;
pc=fork();
if(pc<0) /* 如果出错 */
printf("error ocurred!\n");
else if(pc==0){ /* 子进程 */
printf("This is child process with pid of %d.\n",getpid());
exit(3); /* 子进程返回3 */
}
else{ /* 父进程 */
pr=wait(&status);
if(WIFEXITED(status)){ /* 如果WIFEXITED返回非零值 */
printf("the child process %d exit normally.\n",pr);
printf("the return code is %d.\n",WEXITSTATUS(status));
}else /* 如果WIFEXITED返回零 */
printf("the child process %d exit abnormally.\n",pr);
}
}
waitpid系统调用在Linux函数库中的原型是:
#include <sys/types.h> /* 提供类型pid_t的定义 */
#include <sys/wait.h>
pid_t waitpid(pid_t pid,int *status,int options)
从本质上讲,系统调用waitpid和wait的作用是完全相同的,但waitpid多出了两个可由用户控制的参数pid和options,从而为我们编程提供了另一种更灵活的方式。下面我们就来详细介绍一下这两个参数:
pid
从参数的名字pid和类型pid_t中就可以看出,这里需要的是一个进程ID。但当pid取不同的值时,在这里有不同的意义。
- pid>0时,只等待进程ID等于pid的子进程,不管其它已经有多少子进程运行结束退出了,只要指定的子进程还没有结束,waitpid就会一直等下去。
- pid=-1时,等待任何一个子进程退出,没有任何限制,此时waitpid和wait的作用一模一样。
- pid=0时,等待同一个进程组中的任何子进程,如果子进程已经加入了别的进程组,waitpid不会对它做任何理睬。
- pid<-1时,等待一个指定进程组中的任何子进程,这个进程组的ID等于pid的绝对值。
options
options提供了一些额外的选项来控制waitpid,目前在Linux中只支持WNOHANG和WUNTRACED两个选项,这是两个常数,可以用"|"运算符把它们连接起来使用,比如:
ret=waitpid(-1,NULL,WNOHANG | WUNTRACED);
如果我们不想使用它们,也可以把options设为0,如:
ret = waitpid(-1, NULL, 0);
如果使用了WNOHANG参数调用waitpid,即使没有子进程退出,它也会立即返回,不会像wait那样永远等下去。
察看<内核源码目录>/include/unistd.h文件349-352行就会发现以下程序段,发现wait就是包装过的waitpid。
static inline pid_t wait(int * wait_stat)
{
return waitpid(-1,wait_stat,0);
}
waitpid的返回值比wait稍微复杂一些,一共有3种情况:
- 当正常返回的时候,waitpid返回收集到的子进程的进程ID;
- 如果设置了选项WNOHANG,而调用中waitpid发现没有已退出的子进程可收集,则返回0;
- 如果调用中出错,则返回-1,这时errno会被设置成相应的值以指示错误所在;
当pid所指示的子进程不存在,或此进程存在,但不是调用进程的子进程,waitpid就会出错返回,这时errno被设置为ECHILD;
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
int main()
{
pid_t pc, pr;
pc=fork();
if(pc<0) /* 如果fork出错 */
printf("Error occured on forking.\n");
else if(pc==0){ /* 如果是子进程 */
sleep(10); /* 睡眠10秒 */
exit(0);
}
/* 如果是父进程 */
do{
pr=waitpid(pc, NULL, WNOHANG); /* 使用了WNOHANG参数,waitpid不会在这里等待 */
if(pr==0){ /* 如果没有收集到子进程 */
printf("No child exited\n");
sleep(1);
}
}while(pr==0); /* 没有收集到子进程,就回去继续尝试 */
if(pr==pc)
printf("successfully get child %d\n", pr);
else
printf("some error occured\n");
}
$ ./main
No child exited
No child exited
No child exited
No child exited
No child exited
No child exited
No child exited
No child exited
No child exited
No child exited
successfully get child 101
父进程经过10次失败的尝试之后,终于收集到了退出的子进程。
因为这只是一个例子程序,不便写得太复杂,所以我们就让父进程和子进程分别睡眠了10秒钟和1秒钟,代表它们分别作了10秒钟和1秒钟的工作。父子进程都有工作要做,父进程利用工作的简短间歇察看子进程的是否退出,如退出就收集它。
说是exec系统调用,实际上在Linux中,并不存在一个exec()的函数形式,exec指的是一组函数,一共有6个,分别是:
#include <unistd.h>
int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg, ..., char *const envp[]);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execve(const char *path, char *const argv[], char *const envp[]);
/* 出错返回-1,成功则不反回 */
其中只有execve是真正意义上的系统调用,其它都是在此基础上经过包装的库函数。
带哦用exec并不创建新进程,所以进程ID并未改变,只是用磁盘上一个新的程序替换了当前进程的正文段、数据段、堆段和栈段。
fork会将调用进程的所有内容原封不动的拷贝到新产生的子进程中去,这些拷贝的动作很消耗时间,而如果fork完之后我们马上就调用exec,这些辛辛苦苦拷贝来的东西又会被立刻抹掉,这看起来非常不划算,于是人们设计了一种"写时拷贝(copy-on-write)"技术,使得fork结束后并不立刻复制父进程的内容,而是到了真正实用的时候才复制,这样如果下一条语句是exec,它就不会白白作无用功了,也就提高了效率。
https://www.cnblogs.com/XNQC1314/p/9193305.html
8.2 进程标识¶
每个进程都有一个非负整型表示的唯一进程ID。因为进程ID标识符总是唯一的,常将其用作其他标识符的一部分以保证其唯一性。
虽然是唯一的,但是进程ID是可复用的。当一个进程终止后,其进程ID就成为复用的候选者。大多数UNIX系统实现延迟复用算法,使得赋予新建进程的ID不同于最近终止进程所使用的ID。这防止了将新进程误认为是使用同一ID的某个已终止的先前进程。
ID 为0的进程通常是调度进程,也被称为**交换进程**,是内核的一部分,并不执行磁盘上的任何程序,因此也称为**系统进程**。ID为1的进程通常是init进程,inti进程绝不会终止,是所有孤儿进程的父进程。
每个UNIX系统实现都有它自己的一套提供操作系统服务的内核进程,例如,在某些UNIX的虚拟存储器实现中,进程ID2是页守护进程(page daemon),此进程负责支持虚拟存储器系统的分页操作。
#include <unistd.h>
pid_t getpid(void); /* 返回调用进程的进程ID */
pid_t getppid(void); /* 返回调用进程的父进程ID */
8.3 函数fork¶
一个现有的进程可以调用fork()函数创建一个新的进程。
#include <sys/types.h> /* pid_t declared here */
#include <unistd.h>
pid_t fork(void);
/* 子进程返回0,父进程返回子进程ID */
通过fork()创建的新进程被称为子进程(child process)。特点是fork()函数调用一次,返回两次。子进程的返回值是0,父进程的返回值是新创建的子进程的进程ID。
之所以把子进程ID返回给父进程,是因为一个进程的子进程可以有多个,并且没有一个函数使一个进程可以获得其所有子进程的ID。
子进程是父进程的副本,获得父进程的数据、堆和栈的副本。注意是副本,也就是在子进程的修改对父进程无影响。另外在fork()函数后经常紧随exec,其中exec的作用是根据指定的文件名找到可执行文件,并替代调用进程的内容。
Linux针对fork()后紧随exec这种情况做了优化,因为执行fork()产生一个父进程的副本,需要执行拷贝操作,这些拷贝操作是存在开销的,如果我们执行了fork()后紧随用exec指定的可执行文件替换掉了刚才拷贝的内容,那么刚才的拷贝就失去了意义。于是Linux采用了**写时复制(Copy-On-Write, COW)**技术,fork()后不会立刻制作父进程的副本,而是真正用到的时候才会进行复制。
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>
#include <stdlib.h>
int globalVar = 6;
char buff[] = "a write to stdout\n";
int main()
{
int var = 88;
pid_t pid;
if (write(STDOUT_FILENO, buff, sizeof(buff) - 1) != sizeof(buff) - 1) {
fprintf(stderr, "write error: %s\n", strerror(errno));
exit(EXIT_FAILURE);
}
printf("before fork\n");
if ((pid = fork()) < 0) {
fprintf(stderr, "fork error: %s\n", strerror(errno));
exit(EXIT_FAILURE);
}
else if (pid == 0) { ++globalVar; ++var; }
else sleep(2);
printf("pid = %ld, glob = %d, var = %d\n", (long)getpid(), globalVar, var);
return 0;
}
$ ./main
a write to stdout
before fork
pid = 7175, glob = 7, var = 89
pid = 7174, glob = 6, var = 88
$ ./main > tmp.txt
a write to stdout
before fork
pid = 7177, glob = 7, var = 89
before fork
pid = 7176, glob = 6, var = 88
书中的程序做了一些小的修改,但是不影响知识点:
- 带缓冲的IO和不带缓冲的IO——
write和标准IO。 fork()制作了父进程的副本,子进程对变量的修改不影响父进程。
我们发现,当重定向输出到磁盘文件tmp.txt的时候,多了一行before fork,也就是printf()打印的内容。回顾5.4 缓冲的内容,write函数是不带缓冲的,但是它把数据写出到标准输出流,但是标准输出流可是带缓冲的。根据系统默认的缓冲类型,标准输出连接的是终端设备时,是行缓冲的,也就是write每写入到标准输出流一个字符,就会进行flush,使用printf(),遇到换行符或者写满缓冲区进行flush。所以在fork()执行的时候,缓冲区是空的,所以第一次只输出一句before fork。
后面将标准输出流连接磁盘文件,标准输出的缓冲变成了全缓冲的,意味着即使遇到了printf()的换行符也不会flush。于是在fork()的时候,缓冲区保留了before fork,遇到return 0或者写成exit(0)也可以,他会将缓冲区的内容写回磁盘,所以会被输出两次。
父进程和子进程的区别
fork()的返回值不同,子进程返回0,反进程返回子进程的进程ID。- 进程ID不同;
- 两个进程的父进程ID不同:子进程的父进程ID是创建它的进程ID,父进程的父进程ID无变化。
- 子进程不继承父进程设置的文件锁。
- 子进程的未处理闹钟被清除。
- 子进程的未处理信号集设置为空集。
8.4 函数vfork()¶
vfork和fork一样都用于创建一个新进程,该进程的目的是exec一个新程序。vfork创建子进程,并不将父进程的地址空间完全复制到子进程,而是子进程在父进程的空间中运行,但是如果子进程修改了数据、进行函数调用、或没有调用exec或exit就会带来的未知的后果。另外vfork保证子进程先运行,子进程调用exec或者exit后父进程才会运行。
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>
#include <stdlib.h>
int globalVar = 6;
int main()
{
int var = 88;
pid_t pid;
printf("before vfork\n");
if ((pid = vfork()) < 0) {
fprintf(stderr, "vfork error: %s", strerror(errno));
exit(EXIT_FAILURE);
}
else if (pid == 0) {
++globalVar;
++var;
_exit(0);
}
printf("pid = %ld, glob = %d, var = %d\n", (long)getpid(), globalVar, var);
return 0;
}
$ ./main
before vfork
pid = 205, glob = 7, var = 89
$ ./main > tmp.txt
$ cat tmp.txt
before vfork
pid = 208, glob = 7, var = 89
因为vfork创建的子进程在父进程空间中运行,并且是先运行子进程,子进程对全局变量和局部变量进行了修改,然后执行_exit(0),子进程结束,不会输出打印最后一句进程信息的内容,然后父进程继续运行,打印信息。
另外如果仿照8.1的程序将输出重定向到磁盘文件,仍然只会有一行before vfork,因为子进程在父进程空间下运行,并不会有复制操作,所以无论是行缓冲还是全缓冲,都只有一句。
8.5 函数exit¶
进程存在5种正常终止和3种异常终止方式:
- 在
main函数内执行return语句,等效于调用exit。 - 调用
exit函数。调用各终止处理程序,关闭所有标准I/O流,但是不会处理文件描述符、多进程以及作业控制。 - 调用
_exit函数。在Unix下,_Exit和_exit是同义的,并不冲洗I/O流。 -
当最后一个线程在启动例程中执行
return语句,返回时,进程以终止状态0返回。 -
进程的最后一个线程调用
pthread_exit函数。
#include<stdlib.h>
void exit(int status);
这个系统调用是用来终止一个进程的。无论在程序中的什么位置,只要执行到exit系统调用,进程就会停止剩下的所有操作,清除包括PCB在内的各种数据结构,并终止本进程的运行。
作为系统调用而言,_exit和exit是一对孪生兄弟,它们究竟相似到什么程度,我们可以从Linux的源码中找到答案:
#define NRexit __NR_exit /* 摘自文件include/asm-i386/unistd.h第334行 */
“__NR_”是在Linux的源码中为每个系统调用加上的前缀,请注意第一个exit前有2条下划线,第二个exit前只有1条下划线。
看似好像_exit和exit没有任何区别,但我们还要讲一下这两者之间的区别,这种区别主要体现在它们在函数库中的定义。_exit在Linux函数库中的原型是:
#include<unistd.h>
void _exit(int status);
和exit比较一下,exit()函数定义在stdlib.h中,而_exit()定义在unistd.h中,从名字上看,stdlib.h似乎比unistd.h高级一点,那么,它们之间到底有什么区别呢?让我们先来看流程图,通过下图,我们会对这两个系统调用的执行过程产生一个较为直观的认识。

从图中可以看出,_exit()函数的作用最为简单:直接使进程停止运行,清除其使用的内存空间,并销毁其在内核中的各种数据结构;exit()函数则在这些基础上作了一些包装,在执行退出之前加了若干道工序,也是因为这个原因,有些人认为exit已经不能算是纯粹的系统调用。
exit()函数与_exit()函数最大的区别就在于exit()函数在调用exit系统调用之前要检查文件的打开情况,把文件缓冲区中的内容写回文件,就是图中的“清理I/O缓冲”一项。
在Linux的标准函数库中,有一套称作“高级I/O”的函数,我们熟知的printf()、fopen()、fread()、fwrite()都在此列,它们也被称作“缓冲I/O(buffered I/O)”,其特征是对应每一个打开的文件,在内存中都有一片缓冲区,每次读文件时,会多读出若干条记录,这样下次读文件时就可以直接从内存的缓冲区中读取,每次写文件的时候,也仅仅是写入内存中的缓冲区,等满足了一定的条件(达到一定数量,或遇到特定字符,如换行符\n和文件结束符EOF),再将缓冲区中的内容一次性写入文件,这样就大大增加了文件读写的速度,但也为我们编程带来了一点点麻烦。如果有一些数据,我们认为已经写入了文件,实际上因为没有满足特定的条件,它们还只是保存在缓冲区内,这时我们用_exit()函数直接将进程关闭,缓冲区中的数据就会丢失,反之,如果想保证数据的完整性,就一定要使用exit()函数。
#include <stdlib.h>
#include <stdio.h>
int main()
{
printf("output begin\n");
printf("content in buffer");
exit(0);
}
$ ./main
output begin
content in buffer
如果使用_exit():
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
int main()
{
printf("output begin\n");
printf("content in buffer");
_exit(0);
}
$ ./main
output begin
在一个进程调用了exit之后,该进程并非马上就消失掉,而是留下一个称为僵尸进程(Zombie)的数据结构。在Linux进程的5种状态中,僵尸进程是非常特殊的一种,它已经放弃了几乎所有内存空间,没有任何可执行代码,也不能被调度,仅仅在进程列表中保留一个位置,记载该进程的退出状态等信息供其他进程收集,除此之外,僵尸进程不再占有任何内存空间。
8.6 函数wait和waitpid¶
当一个进程正常或者异常终止时,内核向父进程发送SIGCHLD信号,子进程终止是个异步事件(可以在父进程运行的任何时刻发生),所以这种信号也是内核向父进程发出的异步通知。调用wait或waitpid后:
- 如果所有子进程都还在运行,则阻塞
- 如果一个子进程终止,正等待父进程获取其终止状态,则取得该子进程的终止状态立即返回。
- 如果它没有任何子进程,则立即出错并返回
#include <sys/wait.h>
pid_t wait(int *statloc);
pid_t waitpid(pid_t pid, int *statloc, int options);
//成功返回进程ID,出错返回0或-1
两个函数的区别:
- 在一个子进程终止前,
wait使其调用者阻塞,waitpid有一个选项options使调用者不阻塞。 waitpid并不等待在其调用之后的第一个终止子进程,它有若干选项,可以控制所等待的进程。
两个函数的参数statloc是一个整型指针,如果不是空指针,则终止进程的终止状态就存放在它所指向的单元内;如果不关心终止状态,则可将参数定为空指针。
终止状态用户定义在<sys/wait.h>中的各个宏来查看。有4个**互斥**的宏用来获取进程终止的原因,名字以WIF开头。
| 宏 | 说明 |
|---|---|
WIFEXITED(status) |
正常终止子进程返回的状态则为真,可以通过WEXITSTATUS(status)来获取子进程传给exit或_exit参数的低8位 |
WIFSIGNALED(status) |
异常终止子进程返回的状态则为真,可执行WTERMSIG(status)来获取使子进程终止的信号编号。 |
WIFSTOPPED(status) |
若为当前暂停子进程返回的状态则为真,执行WSTOPSIG(status)获取使子进程暂停的编号 |
WIFCONTINUED(status) |
若在作业控制暂停后已经继续的子进程返回了状态则为真 |
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>
#include <stdlib.h>
#include <sys/wait.h>
void pr_exit(int status)
{
if (WIFEXITED(status)) {
printf("normal termination, exit status = %d\n", WEXITSTATUS(status));
}
else if (WIFSIGNALED(status)) {
printf("abnormal termination, signal number = %d\n", WTERMSIG(status));
}
else if (WIFSTOPPED(status)) {
printf("child stopped, signal number = %d\n", WSTOPSIG(status));
}
}
void err_sys(const char *str)
{
fprintf(stderr, "%s: %s\n", str, strerror(errno));
exit(EXIT_FAILURE);
}
int main()
{
int status;
pid_t pid;
if ((pid = fork()) < 0) err_sys("fork error");
else if (pid == 0) exit(7);
if (wait(&status) != pid) err_sys("wait error");
pr_exit(status); //print the normal status
if ((pid = fork()) < 0) err_sys("fork error");
else if (pid == 0) abort(); //abnormal termination
if (wait(&status) != pid) err_sys("wait error");
pr_exit(status);
if ((pid = fork()) < 0) err_sys("fork error");
else if (pid == 0) status /= 0;
if (wait(&status) != pid) err_sys("wait error");
pr_exit(status);
return 0;
}
normal termination, exit status = 7
abnormal termination, signal number = 6
abnormal termination, signal number = 8
8.9 竞争条件¶
当多个进程都企图对共享数据进行某种处理,而最后的结果取决于进程运行的顺序时,认为发生了**竞争条件(race condition)**。
如果一个进程希望等待某个子进程终止,可以使用wait;一个子进程等待其父进程终止,则可以使用循环:
while (getppid() != 1) sleep(1);
这种形式的循环称为**轮询(polling)**,浪费了CPU的时间。
书中给出了一个存在竞争条件的例子,程序输出两个字符串,一个由子进程输出,一个由父进程输出,输出依赖于两个进程运行的顺序及每个进程运行的时间长度。
#include <stdio.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>
#include <stdlib.h>
#include <signal.h>
void unix_error(char *msg)
{
fprintf(stderr, "%s: %s\n", msg, strerror(errno));
exit(0);
}
pid_t Fork()
{
pid_t pid = fork();
if (pid < 0) unix_error("fork error");
return pid;
}
static void charatatime(char *str)
{
int c;
setbuf(stdout, NULL); // set unbuffered
for (char *ptr = str; (c = *ptr++); ) putc(c, stdout);
}
int main(int argc, char **argv, char **envp)
{
pid_t pid;
if ((pid = Fork()) == 0) {
charatatime("output from child\n");
}
else {
charatatime("output from parent\n");
}
return 0;
}
$ ./main
output from opuatrpeutn tf
rom child
$ ./main
output from parent
output from child
改进的办法就是利用信号规定执行的顺序,为了让父进程先运行,用WAIT_PARENT()让子进程等待父进程完成,父进程完成后通过TELL_CHILD()告诉子进程自己已经完成了,然后子进程收到信号,开始输出。
int main(int argc, char **argv, char **envp)
{
pid_t pid;
TELL_WAIT();
if ((pid = Fork()) == 0) {
WAIT_PARENT(); //parent first
charatatime("output from child\n");
}
else {
charatatime("output from parent\n");
TELL_CHILD(pid); //tell child parent has done
}
return 0;
}
8.10 函数exec¶
8.13 函数system¶
#include <stdlib.h>
int system(const char *cmdstring);
使用system而不是直接使用fork和exec的好处是,system进行了所需的各种出错处理及各种信号处理。
第九章 进程关系¶
9.4 进程组¶
进程组是一个或多个进程的集合。
9.5 会话¶
会话(session)是一个或多个进程组的集合。通常由shell的管道将几个进程编成一组,
第十章 信号¶
信号是软件中断,信号提供了一种处理异步事件的方法。
10.2 信号概念¶
在头文件<signal.h>中,信号名都被定义为正整数常量(信号编号),不存在编号为0的信号,kill函数对信号编号0有特殊的应用。
在某个信号出现时,可以告诉内核按照下列三种方式之一进行处理,称为信号处理或与信号相关的动作。
- 忽略此信号。大多数信号都可以使用这种方式处理,但是
SIGKILL和SIGSTOP不能被忽略,因为它们向内核和超级用户提供了使进程终止或停止的可靠方法。 - 捕捉信号。不能捕捉
SIGKILL和SIGSTOP信号。 - 执行系统默认动作,大多数信号的系统默认动作是终止该进程。
第11章 线程¶
11.3 线程标识¶
线程ID是用pthread_t数据类型来表示的,实现的时候可以用一个结构来代表pthread_t数据类型,所以可移植的操作系统实现不能把它作为整数处理。因此必须使用一个函数来对两个线程ID进行比较。
所说的可移植操作系统,是指有的操作系统用无符号类型或者长整型标识pthread_t,而有的操作系统是用结构体来表示,所以不能单纯的用=来判断,应该使用equal函数。(Linux下用无符号长整型来表示)
#include <pthread.h>
int pthread_equal(pthread_t tid1, pthread_t tid2);
// 如果相等返回非零整数,否则返回0
类似进程ID,我们可以用getpid()来获取进程ID,同样有时候也需要打印线程ID:
#include <pthread.h>
pthread_t pthread_self(void);
//返回值,线程的线程ID
11.4 线程的创建¶
在POSIX线程(pthread)的情况下,程序开始运行,是以单进程中的单个控制线程启动的。
#include <pthread.h>
int pthread_create(pthread_t *tidp, const pthread_attr_t* attr, void* (*start_rtn)(void *), void *arg);
//成功返回0,失败返回错误编号
线程创建成功的时候,线程ID会被设置成tidp指向的内存单元。attr用于控制各种不同的线程属性,一般设置为NULL。start_rtn是一个函数指针,指向我们想要运行的函数的起始地址。arg是想要向函数start_rtn传递的参数,如果想传递多个参数,那么就把这些参数写成一个结构体,然后用一个指针指向结构体即可。
#include <stdio.h>
#include <pthread.h>
#include <sys/types.h> /* pid_t declared here */
#include <unistd.h> /* getpid() declared here */
void printInfo(const char *s)
{
pid_t pid = getpid();
pthread_t tid = pthread_self();
printf("%s pid %d tid %d (0x%lx)\n", s, (int)pid, (int)tid, (unsigned long)tid);
}
void *myFunc(void *ptr)
{
printInfo("New thread: ");
return NULL;
}
int main()
{
pthread_t id;
int val = pthread_create(&id, NULL, myFunc, NULL);
if (val) printf("%s\n", "can not create thread");
printInfo("Main thread: ");
sleep(2);
return 0;
}
Main thread: pid 730 tid -1920137408 (0x7f098d8d0740)
New thread: pid 730 tid -1929574656 (0x7f098cfd0700)
书中的例子里,sleep的目的是为了防止创建的新线程还没来及执行,整个进程就已经终止了。通过这个小实验去体会pthread_create的使用和熟悉用pthread_self()来获取线程ID。通过结果可知道,主进程对应着一个线程,我们又创建了一个新的线程,他么的进程ID一致,线程ID不一致,符合预期。
11.5 线程终止¶
单个线程可以通过3种方式终止:
- 线程简单的从启动例程返回,返回值是线程的退出码
- 线程被同一进程的其他线程取消(
pthread_cancel,只是提出请求) - 线程自身调用
pthread_exit。
#include <pthread.h>
void pthread_exit(void *rval_ptr);
int pthread_join(pthread_t tid, void** rval_ptr);
//成功返回0, 失败返回错误编号
pthread_join中的rval_ptr用来记录线程的退出码,等待tid指定的线程终止。pthred_exit的参数是一个void*指针,当调用时,其指定的内存单元被设置成PTHREAD_CANCELED。
#include <stdio.h>
#include <pthread.h>
void *func1(void *ptr)
{
printf("%s\n", "thread 1 returning");
return (void*) 1;
}
void *func2(void *ptr)
{
printf("%s\n", "thread 2 exiting");
pthread_exit((void*)2);
}
int main()
{
pthread_t tid1, tid2;
if (pthread_create(&tid1, NULL, func1, NULL)) printf("%s\n", "create thread error");
if (pthread_create(&tid2, NULL, func2, NULL)) printf("%s\n", "create thread error");
void *res1, *res2;
if (pthread_join(tid1, &res1)) printf("%s\n", "can not join thread 1");
printf("thread 1 exit code id %ld\n", (long)res1);
if (pthread_join(tid2, &res2)) printf("%s\n", "can not join thread 2");
printf("thread 2 exit code id %ld\n", (long)res2);
return 0;
}
thread 1 returning
thread 2 exiting
thread 1 exit code id 1
thread 2 exit code id 2
上面的例子很好的说明了线程终止的第一种和第三种情况。
线程可以通过pthread_cancel函数**请求**取消同一进程中的其他线程。
#include <pthread.h>
int pthread_cancel(pthread_t tid);
//成功返回0,错误返回错误编号
pthread_cancel函数会使tid标识的线程像调用了pthread_exit函数一样的效果。但是线程可以忽略或取消这种请求。